In parts one through three, we set up a web server, connected it to a domain name, and instituted some basic security. Now comes the fun part! The web server is humming along doing its thing, and we can watch and admire, making little improvements here and there. It’s not required, but for some, this is part of the payoff.
A webserver needs weeding and watering
It can be counterintuitive that a thing made out of code should need ongoing attention and care. On the surface it seems like it should be self-sufficient, like a wall made of stones. We put the pieces in place where we want them and when we’re happy with it, we stop. It's all silicon and bits after all, why should it need watching?
The bigger picture, though, is that the web server operates in a world that’s always changing. Software updates cause tools to behave differently. Edits happen to the HTML and other content we host. There are dramatic changes in who is trying to reach the content and for what purposes. There can be outages, policy changes, and any number of second-order effects in the wider world that can make our web server stop operating the way we want. So on that scale a web server starts to more closely resemble a vegetable garden—something growing, decaying, and very much a product of the environment that it's in.
This page is my notes on care and feeding practices I've found helpful and enjoyable. I'm not an expert on this, and this is not authoritative by any means. But I put it here in case you find it helpful. If I missed anything, or got it egregiously wrong, please let me know.
Setting
In these examples I'm working with a
DigitalOcean droplet at 138.197.69.146
hosting the content for the domain brandonrohrer.com. It's running
an nginx server on Ubuntu 24.04.
My local machine is a MacBook pro, where I'm working
from the Terminal. My go-to text editor is vim, but you can use nano
instead. Adjust the snippets below for your situation.
Browse the logs
I've been curious about self-hosting for a while, but the thing that pushed me over the edge into migrating off Netlify was a desire to see which IP addresses were visiting which pages when. This information is all in the logs.
Because I set up a server block specifically for my domain,
the log files live in /var/log/nginx/brandonrohrer.com/.
access.log has the main logs, and error.log keeps a log of when
things go poorly.
To browse the logs
cat /var/log/nginx/brandonrohrer.com/access.log
which gives something like
49.51.195.195 - - [14/Sep/2025:08:20:50 -0400] "GET /hosting2 HTTP/1.1" 200 5957 "-" "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1" 183.98.90.239 - - [14/Sep/2025:08:20:50 -0400] "GET /images/ml_logo.png HTTP/1.1" 301 178 "https://www.brandonrohrer.com/blog.html" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36" 24.126.100.175 - - [14/Sep/2025:08:21:02 -0400] "GET /feed.xml HTTP/1.1" 304 0 "-" "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:136.0) Gecko/20100101 Firefox/136.0" 52.187.246.128 - - [14/Sep/2025:08:21:16 -0400] "GET /transformers.html HTTP/1.1" 200 36194 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot"
or
cat /var/log/nginx/brandonrohrer.com/error.log
which gives errors like
2025/09/14 00:37:00 [error] 187956#187956: *28044 access forbidden by rule, client: 78.153.140.50, server: brandonrohrer.com, request: "GET /.env.bak HTTP/1.1", host: "138.197.69.146" 2025/09/14 00:37:00 [error] 187956#187956: *28045 access forbidden by rule, client: 78.153.140.50, server: brandonrohrer.com, request: "GET /mail/.env.db HTTP/1.1", host: "138.197.69.146" 2025/09/14 00:37:01 [error] 187956#187956: *28046 access forbidden by rule, client: 78.153.140.50, server: brandonrohrer.com, request: "GET /dev/.env.old HTTP/1.1", host: "138.197.69.146" 2025/09/14 00:37:01 [error] 187956#187956: *28047 access forbidden by rule, client: 78.153.140.50, server: brandonrohrer.com, request: "GET /crm/.env.bak HTTP/1.1", host: "138.197.69.146"
Scanning through these for a few minutes can reveal some fascinating patterns, a few of which will pop up later in the post.
Check for missed pages
With a slight tweak, this command can pull out only the logs containing a "404", the http status code for Page Not Found. (It actually pulls out every log that has a 404 anywhere in it, but the majority of these are page not found entries.)
cat /var/log/nginx/brandonrohrer.com/access.log | grep 404
This slice of the logs reveals files I don't have, but are normal to
look for, like /favicon.ico and /.well-known/traffic-advice. It
also showed mistakes like a misspelled filename or a missing image.
Catch pages without the .html
One of the first surprises I got was looking 404's in the logs was
that visitors coming to my page looking for a page called
transformers.html would be turned away if they only put in transformers.
There were a lot of 404 log entries for misses of this sort. This was
a bummer. These were people who are trying to visit my website but
are being denied on a technicality.
Luckily nginx makes it straightforward to fix this. I edited the file containing the server block
sudo vi /etc/nginx/sites-available/brandonrohrer.com
and changed the line that read
try_files $uri $uri/ =404;
so that it read
try_files $uri $uri.html $uri/ =404;
When nginx parses the webpage being requested, $uri is the variable
containing the page name. The modified line instructs the server to
first try the exact page name requested, then to try it with a .html
tagged onto the end, then to try it with a backslash on the end, and if
none of those turn anything up, return a 404 page not found error.
After making this change (or any of the other changes described below) it's important to first test that we didn't goober anything up
sudo nginx -t
and if our change passes the test and nginx is happy with it, then restart nginx so that the change takes effect
sudo systemctl restart nginx
Redirects
In addition to accounting for missing html extensions, I've found it helpful
to automatically expand short names into longer ones.
For example, numba automatically redirects to numba_tips.html.
It's also good for fixing typos in published pages. I've
redirected statistics_resources.html to stats_resources.html because
I shared the wrong URL in a publication.
I also use it as a link shortener, so that fnc actually points to a pdf
in a codeberg repository and bp redirects to a video about
backpropagation on youtube. For the record, brandonrohrer.com is a
terrible domain name for a link shortener. I also picked up tyr.fyi
as a shorter domain for when I want erally short links.
https://www.digitalocean.com/community/tutorials/nginx-rewrite-url-rules
Redirects are implemented in the domain's server block.
sudo vi /etc/nginx/sites-available/brandonrohrer.com
Add a line like this within the server block.
location = /numba {
return 301 $scheme://brandonrohrer.com/numba_tips.html;
}
This instruction tells the server to look for a request that looks like
brandonrohrer.com/numba and forwards the request to
brandonrohrer.com/numba_tips.html. $scheme preserves the http or
https, whatever was used in the original request.
Similarly, these lines take any request like brandonrohrer.com/bp
and redirect it toward a specific video URL.
location = /bp {
return 301 https://www.youtube.com/watch?v=6BMwisTZFr4;
}
Location blocks
Redirects are an example of what can be done with location blocks. They can also be used to rewrite requests, or block access.
In addition to exact matching on page names, location blocks can match on partial names, directories, and regex-specified patterns. They give fine grained control for how individual pages are accessed and even which IP addresses are allowed to access them, but they can quickly become complicated. Individual requests can match multiple location blocks, and the match is not determined on a first-come, first-served bases, but rather based on a set of rules. Use with due caution. The DigitalOcean docs on how location blocks get matched are a great resource if you want to dig into this.
Set up log rotation
By default, access logs are stored in access.log and error logs are
stored in error.log and those files just keep getting longer and longer.
I find it really helpful to have one an automatic log rotation in place
where each file contains just one day's access logs or errors. Todays
are called access.log and error.log, yesterday's are
access.log.1 and error.log.1, and the day before that
access.log.2, et cetera, covering the last couple of weeks.
(Starting at day 2 they are also gzipped.) There is
a great guide
to setting this up in the DO docs. The meat of the setup involves
modifying the file /etc/logrotate.d/nginx
After modifying it, this is what my log rotation config looks like
/var/log/nginx/brandonrohrer.com/*.log {
daily
missingok
rotate 14
compress
delaycompress
notifempty
create 0644 www-data adm
sharedscripts
prerotate
if [ -d /etc/logrotate.d/httpd-prerotate ]; then \
run-parts /etc/logrotate.d/httpd-prerotate; \
fi \
endscript
postrotate
invoke-rc.d nginx rotate >/dev/null 2>&1
endscript
}
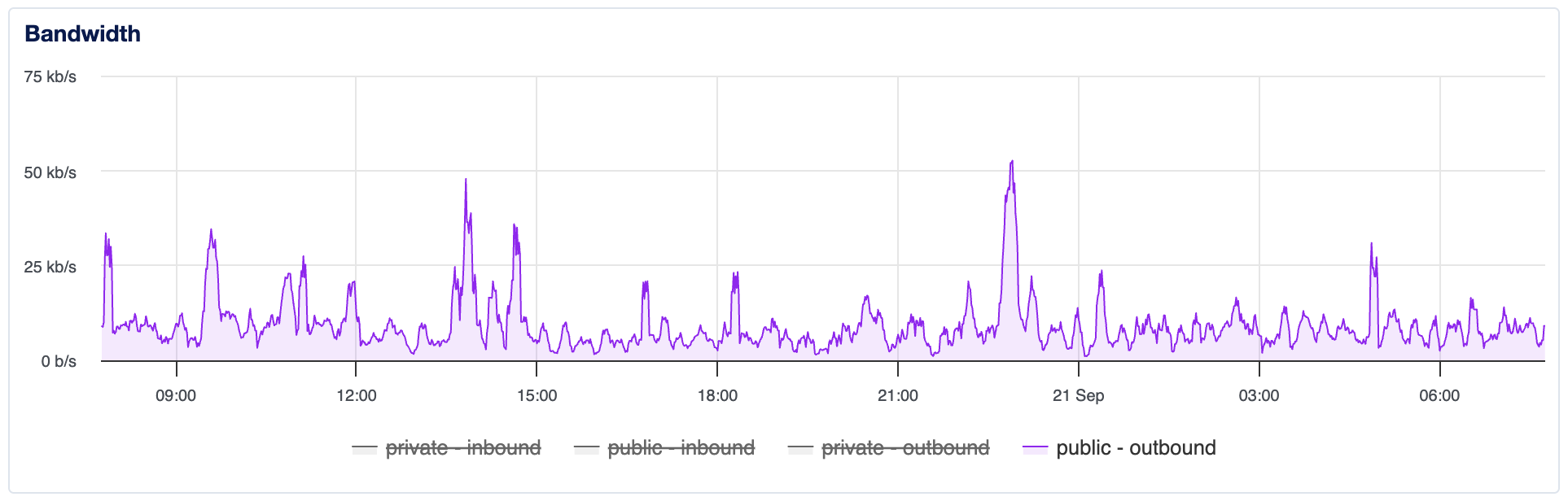
Find a content provider for larger files
If you start offering files larger than a couple megabytes and you start getting more than a handful of views per day, your bandwidth requirements can climb quickly. One way around this is to keep your large files like video, audio, and big images, and other beefy files somewhere other than your web server.
There are several services that offer image, audio, and video hosting, and some of them have free tiers. YouTube is a popular option for hosting vides, but I find ads and irrelevant recommendations so annoying that I've paid a few dollars for a bottom-tier Vimeo account. I don't do a lot of audio-only content, so no recommendations there. My biggest bandwidth hog is my image catalog. I explored using a content hosting service for them but wasn't interested in all the bells and whistles. I eventually settled on abusing GitHub as a hosting service. There seem to be no limitations on repository size, no throttling on bandwidth (at least at the scales I'm using it for) and I'm OK with the trade-off of free hosting in exchange for giving Microsoft unfettered access to my images.
As a result the bandwidth from my server tends to settle around 10 kB/s on average, while serving a few thousand page views per day. It helps me keep my hosting costs low.